System design
Defined the end-to-end workflow across ingestion, validation, enrichment, and output.

AI is only as useful as the data it can be trusted to work with.
At Fleet Space, one of the product challenges sitting underneath exploration workflows was not just analysis or modelling — it was ingestion. Data arrived from multiple sources in inconsistent formats, with missing fields, conflicting structures, and assumptions that were often invisible to the people relying on the outputs. By the time issues surfaced, the data had usually already moved downstream.
That made ingestion more than a technical pipeline problem. It made it a product problem.
I led the design of Exocore as an AI-assisted workflow for turning fragmented raw inputs into structured, validated, decision-ready data — with human judgement kept firmly in the loop.
Concept vision for Exocore as an AI-assisted data foundation connecting ingestion, review, enrichment, and downstream exploration workflows.
Exocore is an AI-enabled data foundation and workflow layer for mineral exploration. It is designed to ingest fragmented exploration data, interpret its structure, enrich it, and prepare it for downstream use in products such as visualisation, targeting, modelling, and decision support.
At a practical level, Exocore sits between raw exploration data and the tools people use to act on that data. It helps turn disconnected files, inconsistent schemas, and messy technical inputs into something more structured, traceable, and usable.
Rather than being a single front-end app, Exocore is better understood as a core platform capability: part ingestion engine, part orchestration layer, part review workflow, and part data-preparation system for AI-assisted exploration products.
On paper, the system could ingest, process, and transform incoming data. From an engineering point of view, that sounded fine.
From a user’s point of view, it was much less convincing.
Files were uploaded. Processing happened somewhere in the background. Results eventually appeared. But users had limited visibility into what had been recognised, what had been standardised, what had failed, what had been corrected automatically, and what still needed human review.
That opacity created a trust gap.
And in this context, a trust gap is not a minor UX issue. If users cannot see how data has been interpreted or changed, they cannot confidently rely on what comes next — whether that is modelling, targeting, reporting, or further automation.
The problem was not that the pipeline existed. The problem was that the most important decisions inside it were effectively hidden.
In practice, I was operating as the principal design lead across strategy, UX, systems, and delivery. This wasn’t a surface-level UI problem. It required rethinking how the system behaved, how it communicated, and how users interacted with it at every stage.
Defined the end-to-end workflow across ingestion, validation, enrichment, and output.
Designed how AI suggestions are surfaced, explained, and controlled by users.
Reframed ingestion as a visible, user-driven process rather than a backend operation.
Worked closely with geophysics, engineering, and product to ensure the system reflected real workflows.
The turning point in this work was recognising that ingestion was being treated as infrastructure when it should have been treated as interaction.
Initially, this stage sat in the background: necessary, technical, and largely invisible. But the more closely we looked, the clearer it became that this was where some of the highest-risk decisions were being made. Structure was inferred. Fields were mapped. Units were interpreted. Inconsistencies were resolved. Missing or malformed data was handled. Every one of those actions had consequences downstream. So the question changed.
Not: How do we process this data?
But: How do we help people understand, review, and trust what is happening to their data before it shapes further decisions?
That shift changed the entire design problem. Exocore needed to behave less like a hidden pipeline and more like a guided, inspectable workflow.
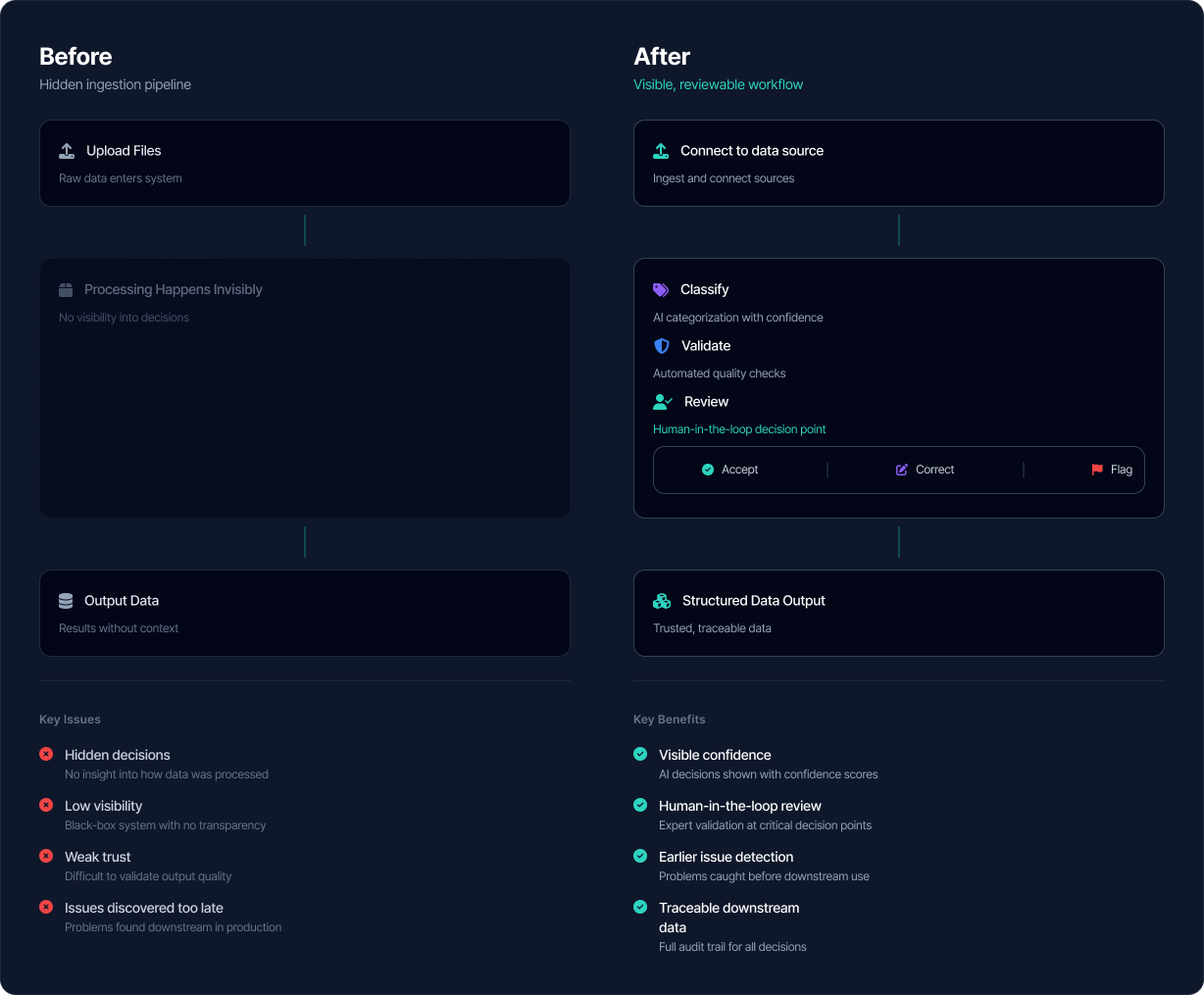
The key design shift was moving from a hidden ingestion pipeline to a visible, reviewable workflow where confidence, validation, and intervention were explicit.
Before Exocore, exploration data was often spread across files, folders, and systems, inconsistently structured, hard to validate quickly, missing context, and risky to use without significant manual checking.
With Exocore, that same data could be ingested in a more structured way, assessed for quality and confidence, reviewed through a visible workflow, enriched or standardised, and prepared for use by downstream tools and teams.
Different roles interacted with the system in different ways, but they were all navigating the same underlying uncertainty. Exocore is for people working in exploration environments where data quality, trust, and speed to insight matter.
That includes:
Exploration geologists and geoscientists
People who need to work with incoming technical data and eventually use it to interpret the subsurface, assess prospectivity, and support exploration decisions.
Data stewards / technical data managers
People responsible for making sure incoming files are usable, correctly structured, and not quietly introducing errors into downstream workflows.
Product and technical teams inside an exploration platform
Teams building experiences such as visualisation, targeting, AI-assisted analysis, and reporting, who need cleaner, more reliable data to make those products useful.
Operational and leadership stakeholders
People who need confidence that what they are seeing in dashboards, targeting outputs, or models is grounded in data that has been meaningfully reviewed and prepared — not just uploaded and passed through a black box.
Exploration geoscientists needed quick access to data they could use without spending hours cleaning it first. Data stewards were responsible for ensuring consistency across datasets — aligning formats, units, and structures so that everything could be compared meaningfully. Technical stakeholders needed confidence that any transformations applied by the system were correct, traceable, and reversible.
Despite these differences, the core job was remarkably consistent:
Take fragmented, inconsistent data and turn it into something that can be trusted for decision-making.
This wasn’t about convenience. It was about confidence.
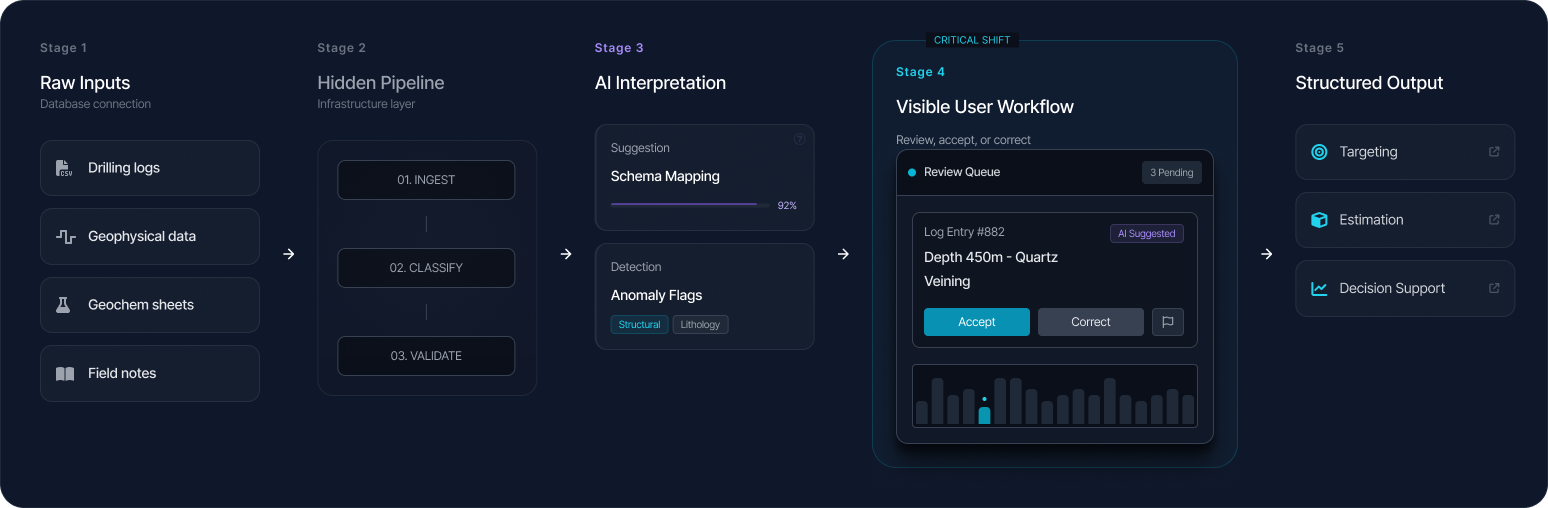
Once the problem was framed around trust, the structure of the system became clearer. At a high level, the workflow followed a simple progression:
Sources → Ingest → Classify → Validate → Enrich → Serve
But the value of the system didn’t come from these steps existing. It came from how each step was exposed to the user.
At every stage, the system needed to answer three things:
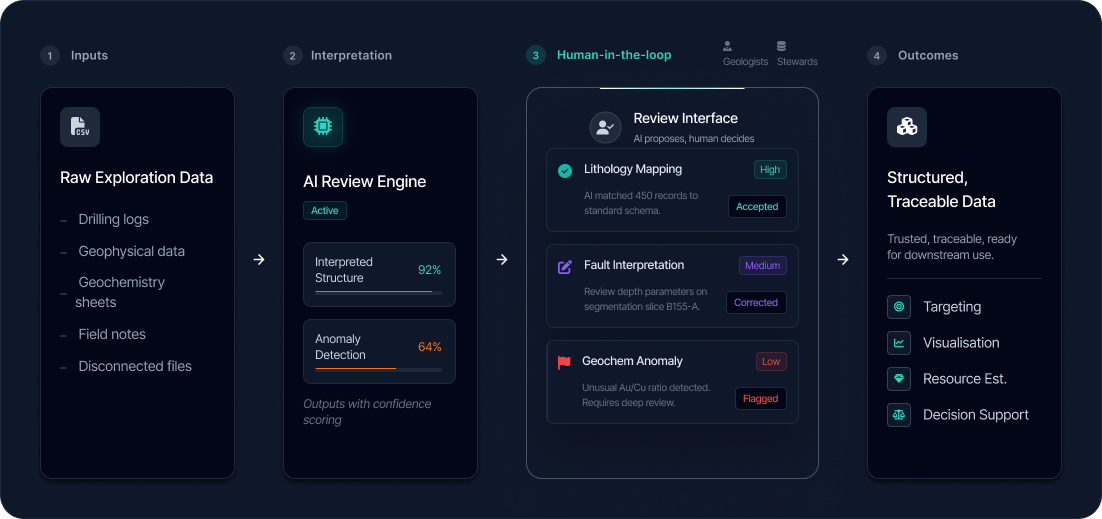
Exocore surfaced AI suggestions with confidence levels and created clear review paths so technical users could accept, correct, or escalate before data moved downstream.
The first move was to make previously hidden system behaviour legible.
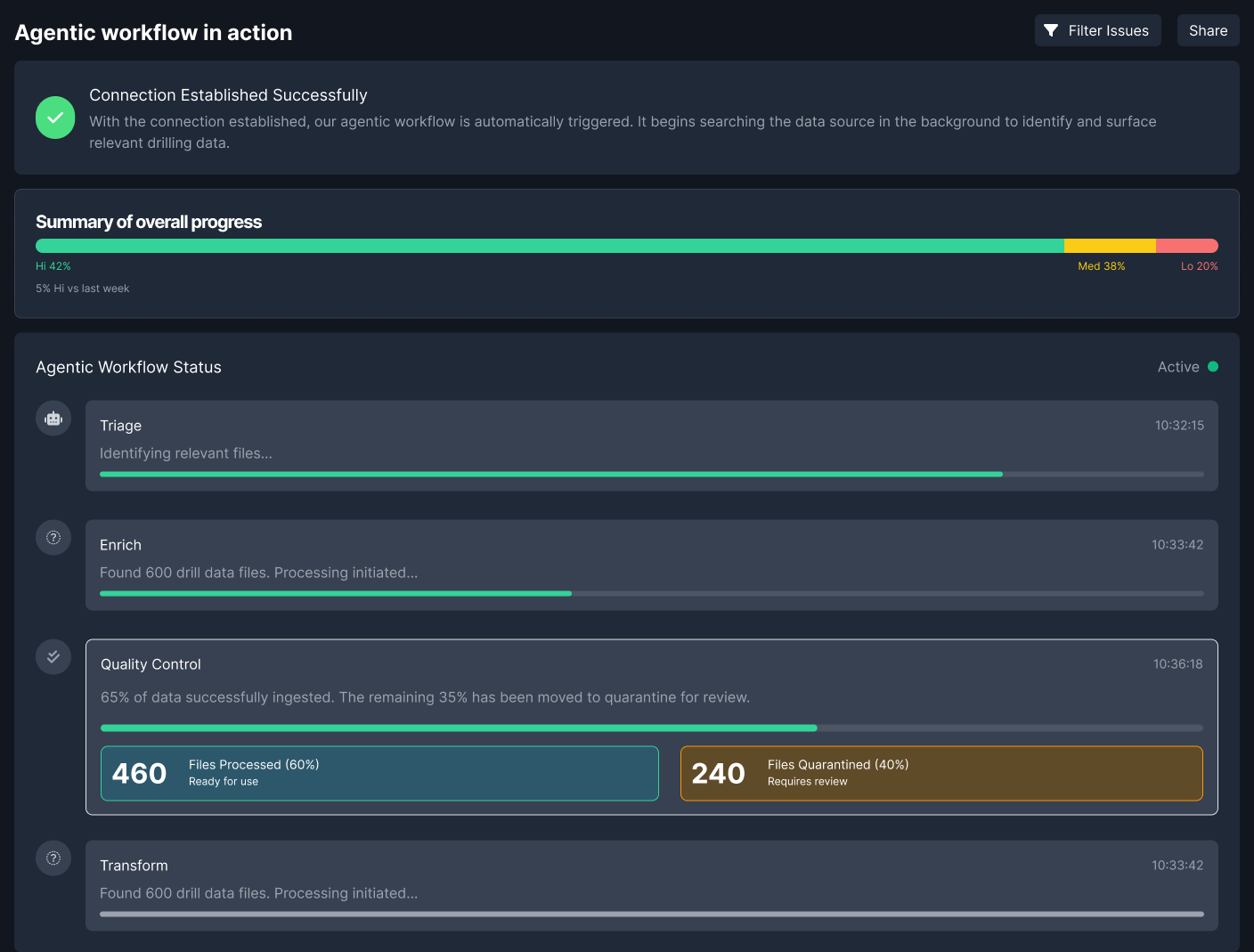
Users needed to see where data was in the process, what the system had inferred, where uncertainty sat, and where intervention was needed. Surfacing pipeline state was not just a transparency feature — it was the foundation for confidence.
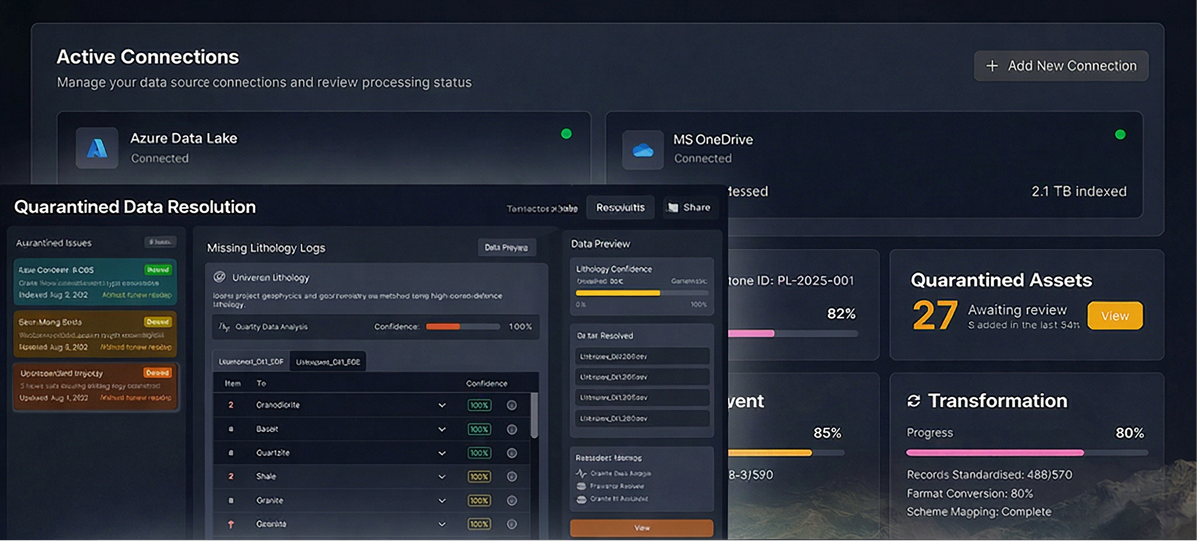
Rather than hiding ingestion behind system processes, the workflow exposed progress, quarantined assets, and confidence distribution so teams could understand what was ready, what was blocked, and what needed review.
AI could detect structure, suggest mappings, identify anomalies, and propose standardisations. But those actions could not remain invisible or feel final by default.
Suggestions were surfaced with explanation and confidence signals, so users could review, accept, adjust, or challenge them. That made the workflow faster without turning it into a black box.
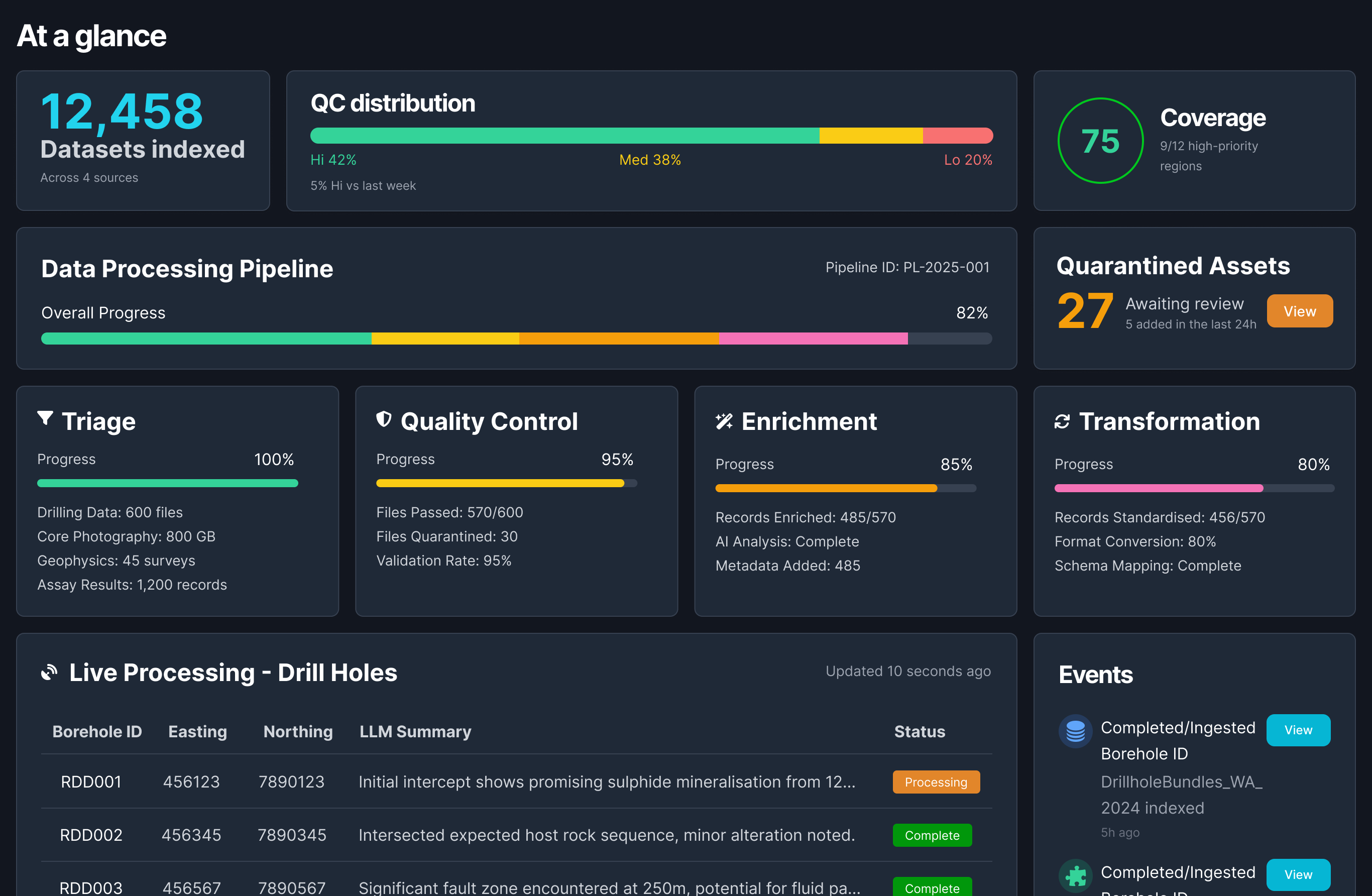
An oversight layer gave teams a quick read on dataset quality, pipeline status, quarantined assets, and stage-level progress across ingestion and transformation.
One of the most important structural changes was moving validation earlier in the flow. Instead of letting questionable data travel downstream and become harder to diagnose later, the system surfaced issues at the point where they were still understandable and contained.
That reduced rework, improved traceability, and made the entire workflow feel more reliable.
Validation became a visible part of the product workflow rather than a hidden backend concern, helping teams intervene earlier and with greater confidence.
Across the workflow, users were effectively asking the same thing:
Can I trust this enough to use it?
The product needed to answer that directly. Confidence indicators, validation summaries, traceable changes, and visible unresolved issues all helped make trust something the interface communicated explicitly instead of leaving it to guesswork.
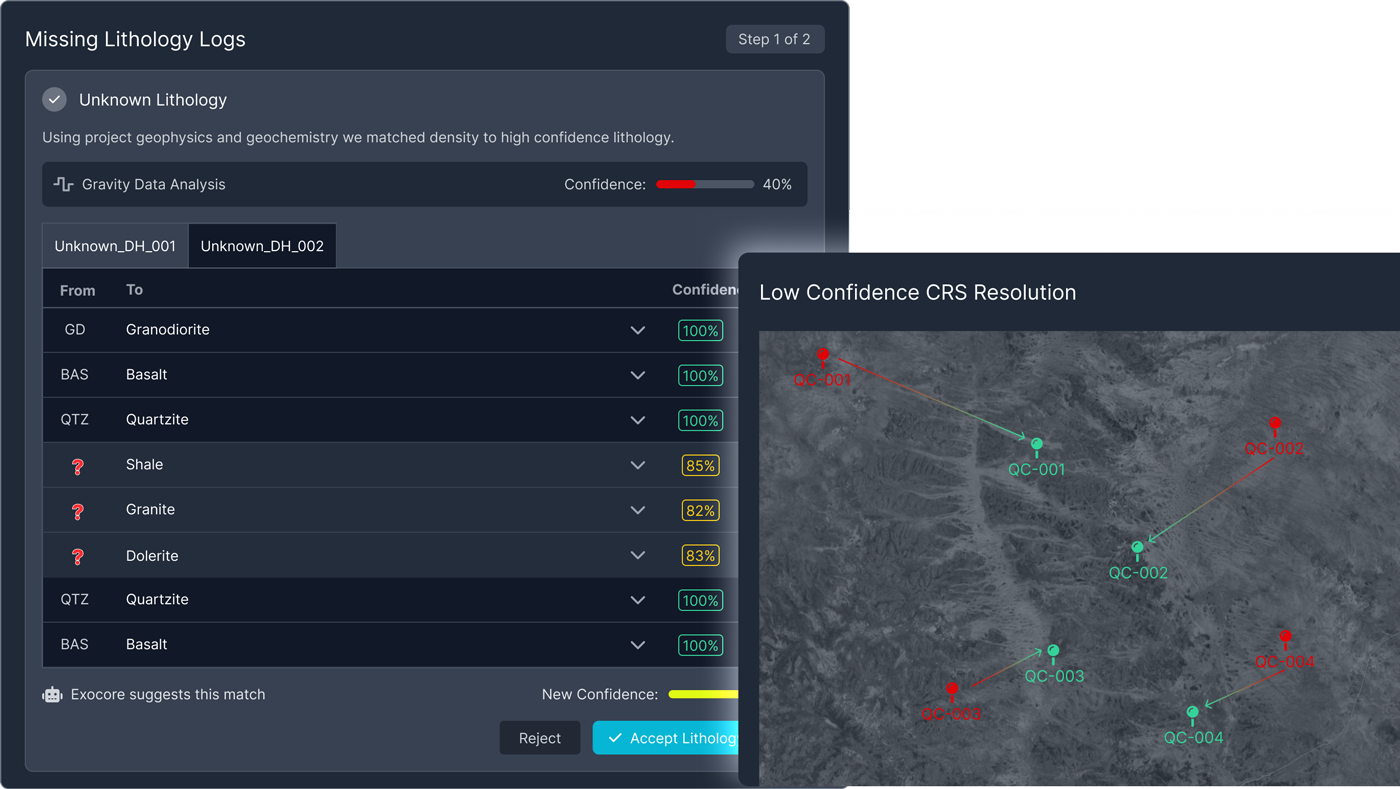
Low-confidence or ambiguous records were routed into review workflows where users could inspect suggested mappings, resolve issues, and decide whether data was ready to promote.
The final system is not just a pipeline. It is a guided workflow that combines automation with human oversight.
Integrates multiple data sources, including cloud storage and uploaded files.
Automatically detects structure while allowing users to adjust mappings.
Surfaces inconsistencies and errors as data enters the system.
Suggests improvements based on contextual understanding of the data.
Provides a clear view of pipeline health and outstanding issues.
This system became foundational across Fleet’s product suite.
It feeds structured data into Exosphere for visualisation, supports analysis workflows in Comet, and integrates with field data collection tools. Everything downstream depends on the quality of what happens here. Which makes this layer disproportionately important.
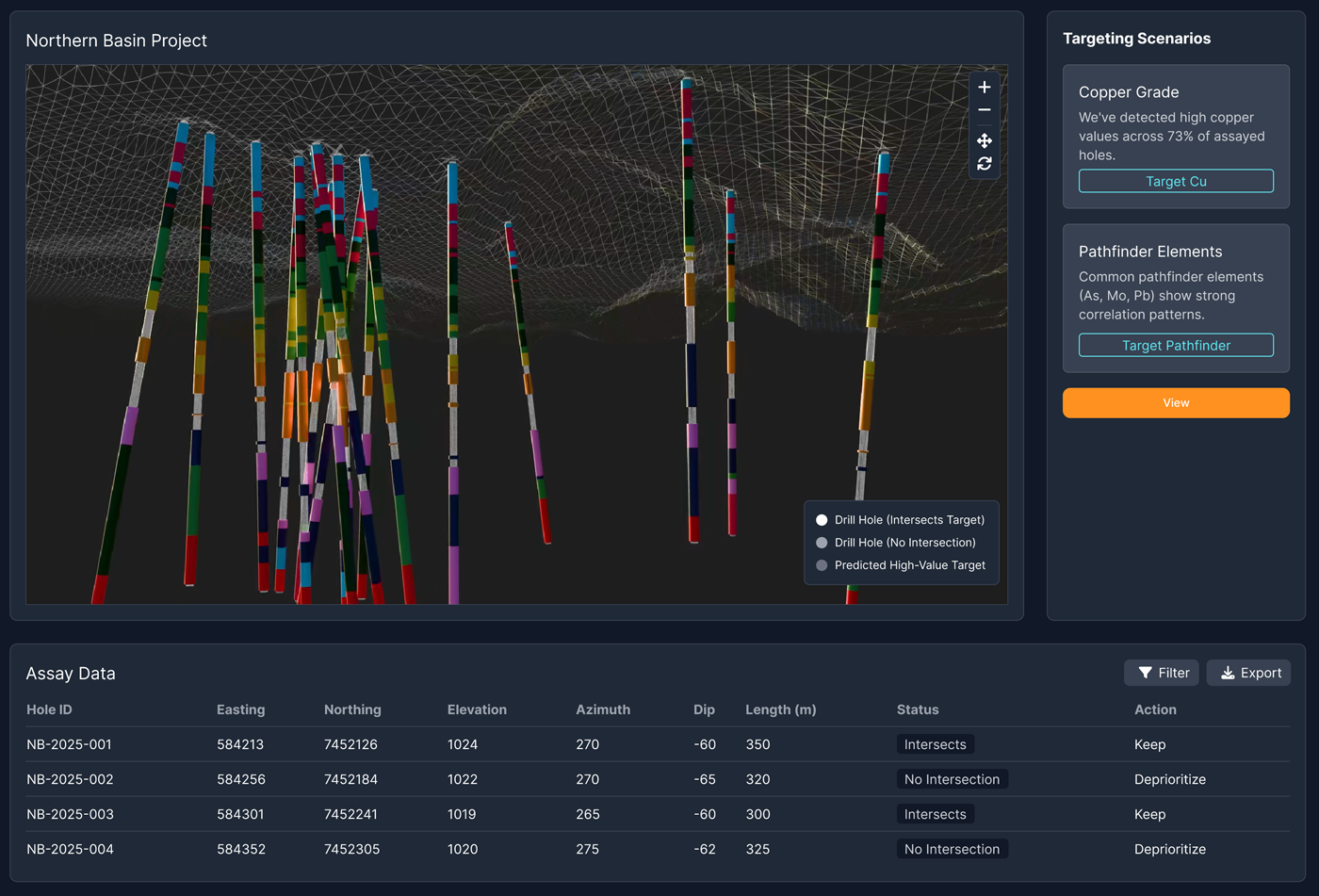
Once data was structured, validated, and traceable, it could support downstream exploration workflows such as targeting scenarios, 3D interpretation, and decision support.
The impact was both operational and perceptual.
This project reinforced something that is easy to overlook: Data systems are not just technical constructs.
They are experiences. If users cannot see, understand, or trust what a system is doing, they will either work around it or disengage from it entirely. Designing for clarity and trust at this layer doesn’t just improve the pipeline.
It changes how decisions are made.